Visual Prompting
Yesterday, Andrew Ng announced a new achievement for landing.ai, which contributes to advancing computer vision models.
Andrew explains "Visual Prompting" in a live stream in which he showed what we can do using it.
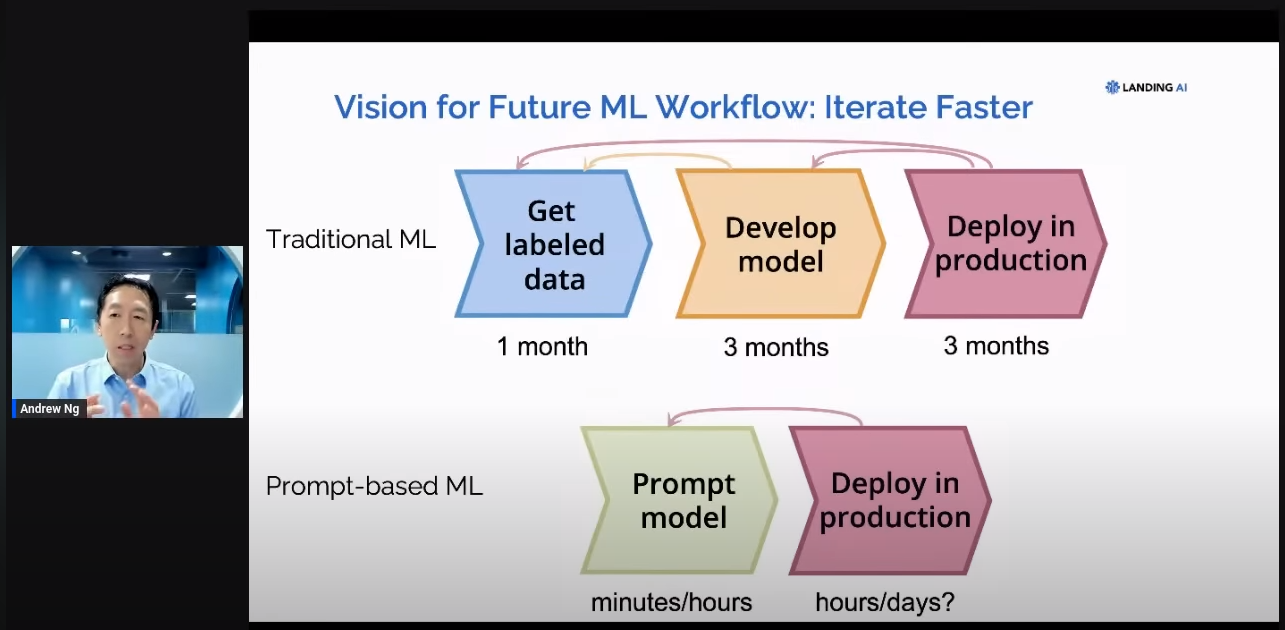
It allows us to train a model using prompts, this is different than the traditional training setup.
In the traditional way, we collect data (which is a difficult task), we build a model, and we train it on the data.
In the Visual Prompting way, we show the model an example through interactive labelling on the image (see the pictures), and then the model is ready for inference.
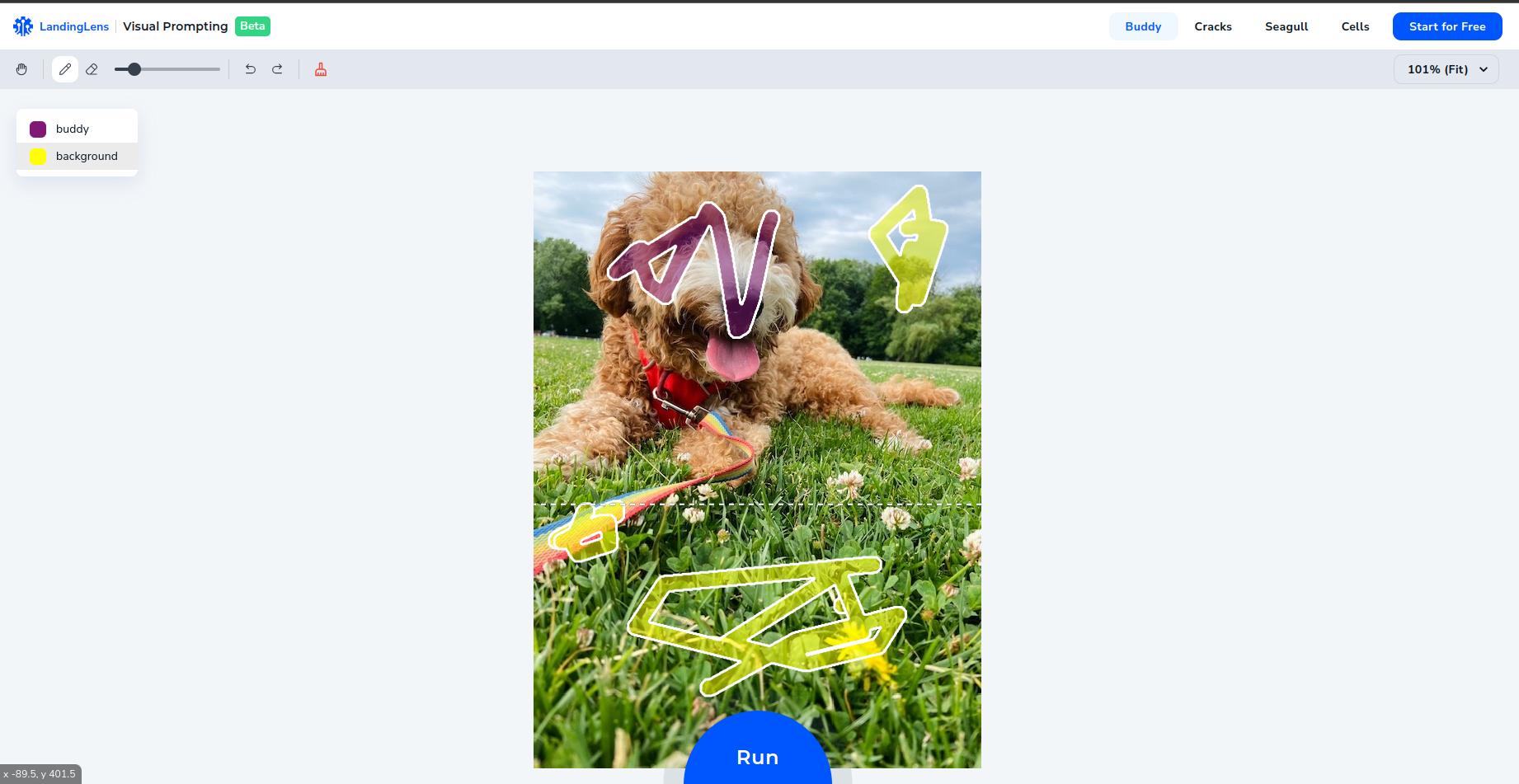
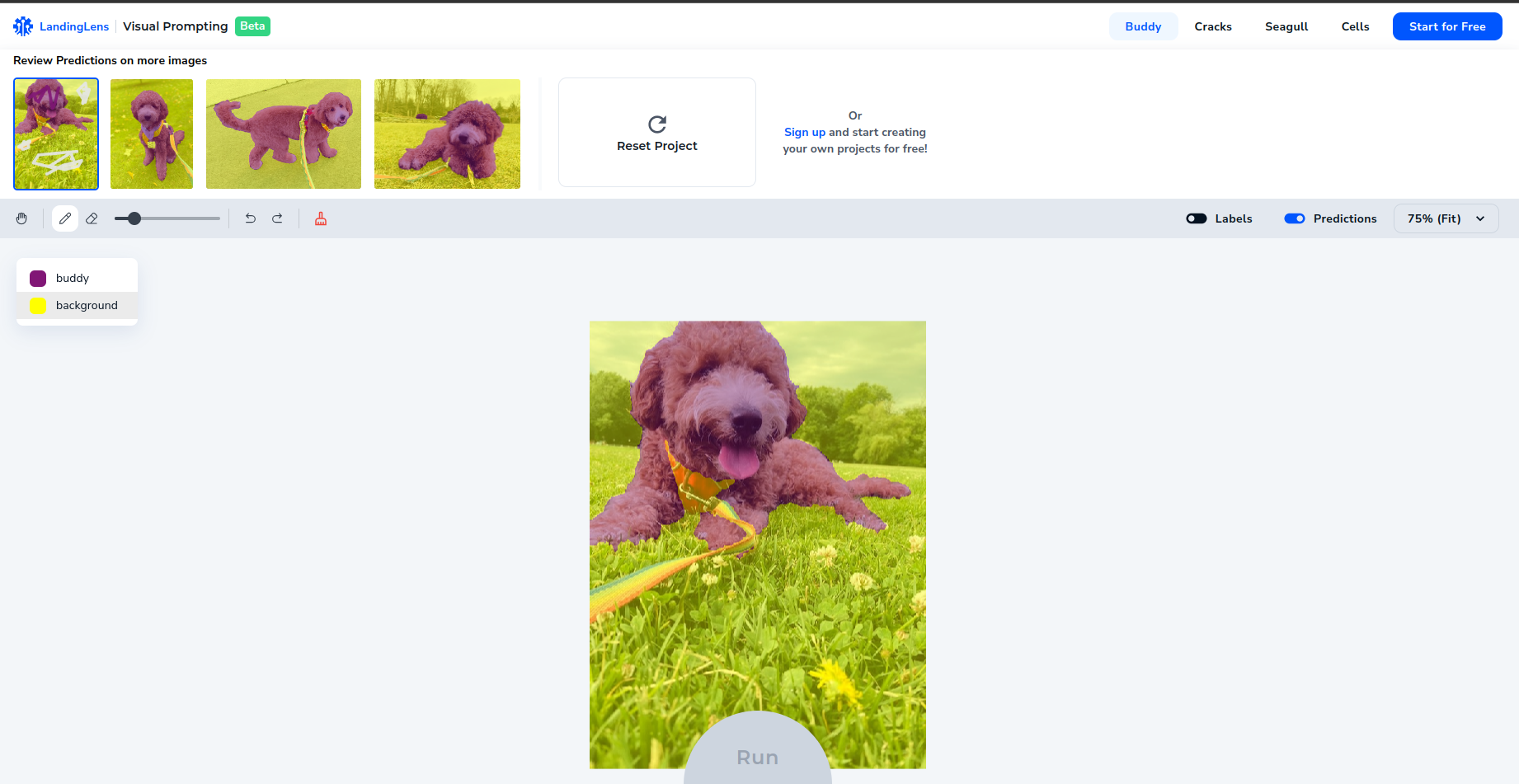
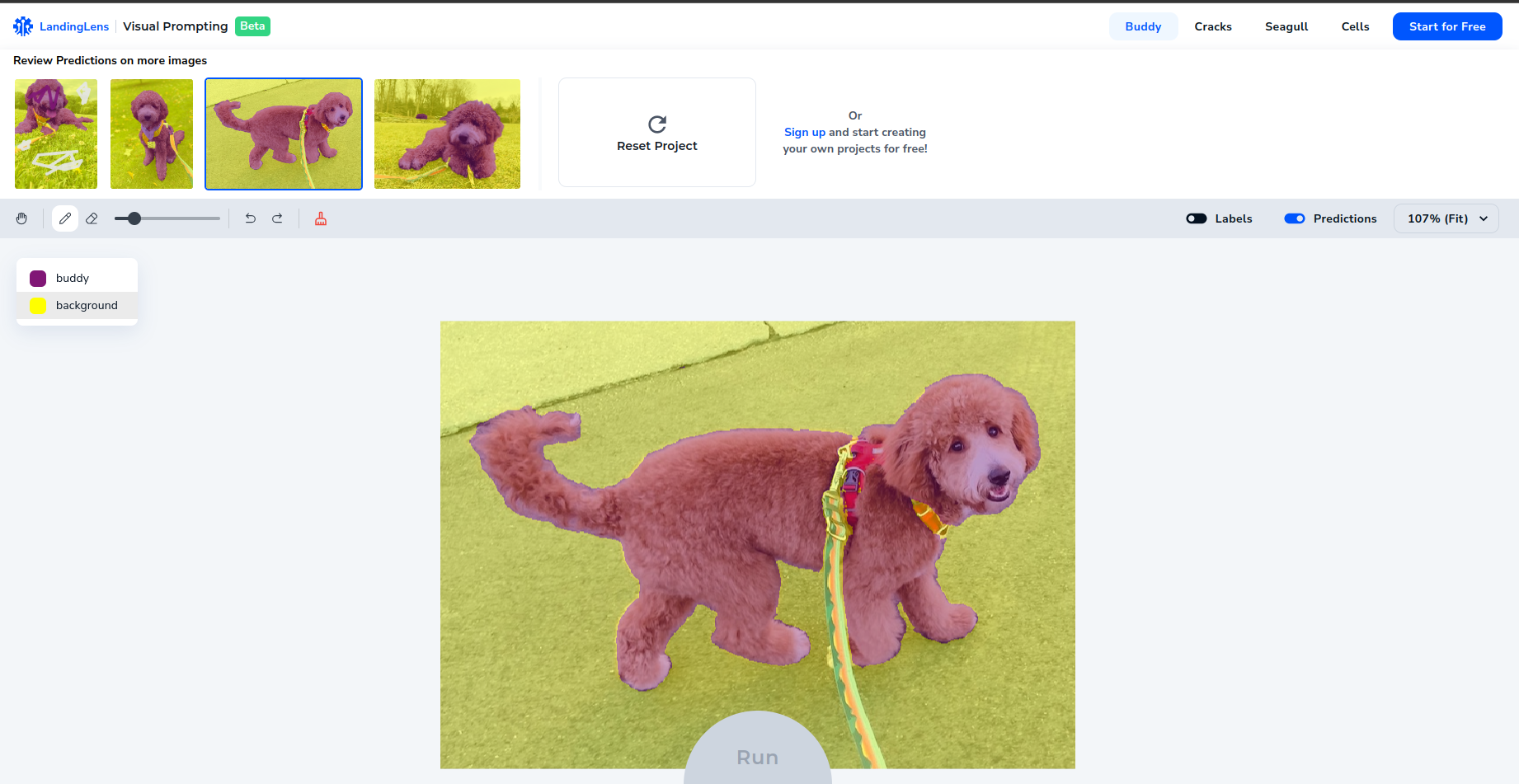
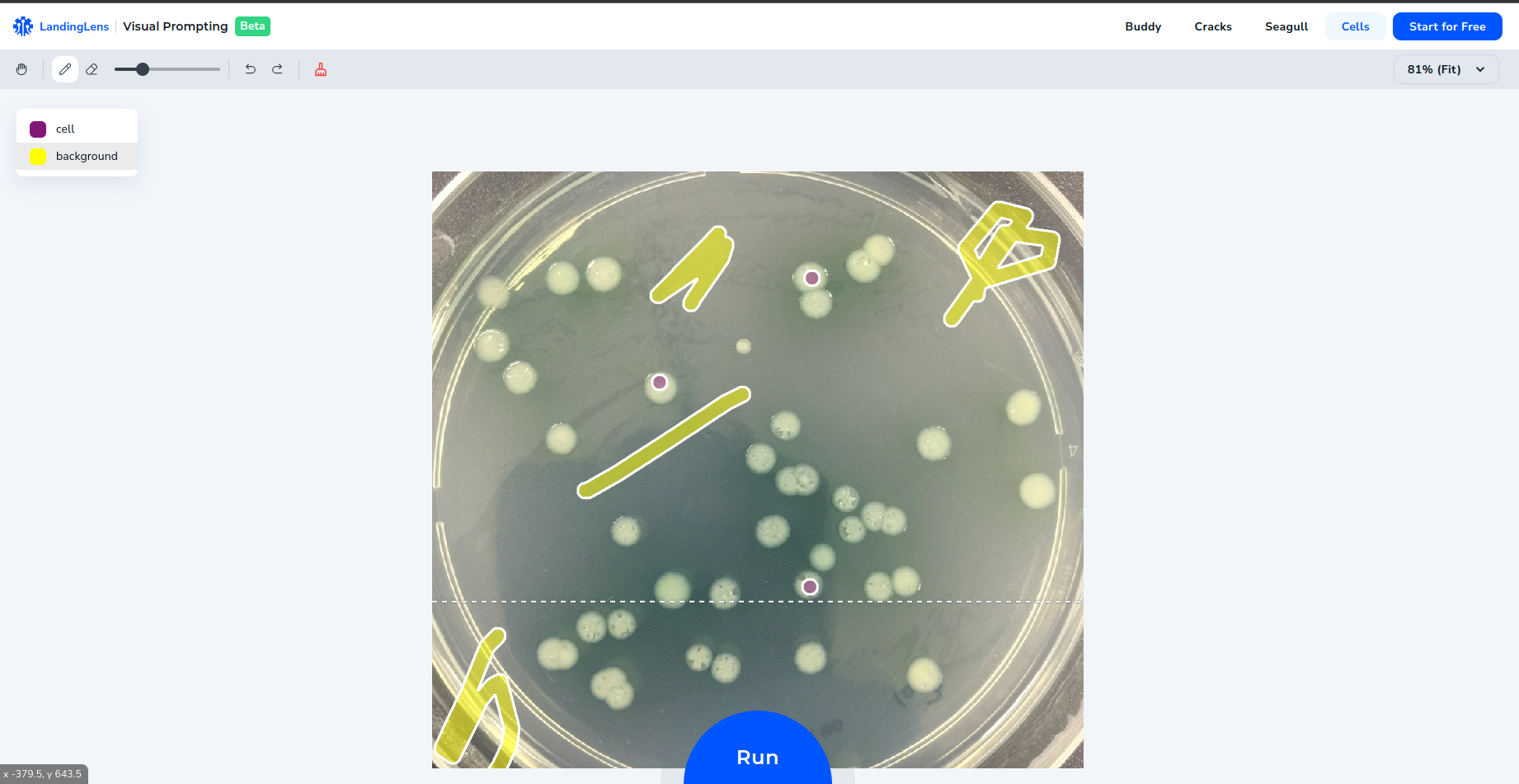
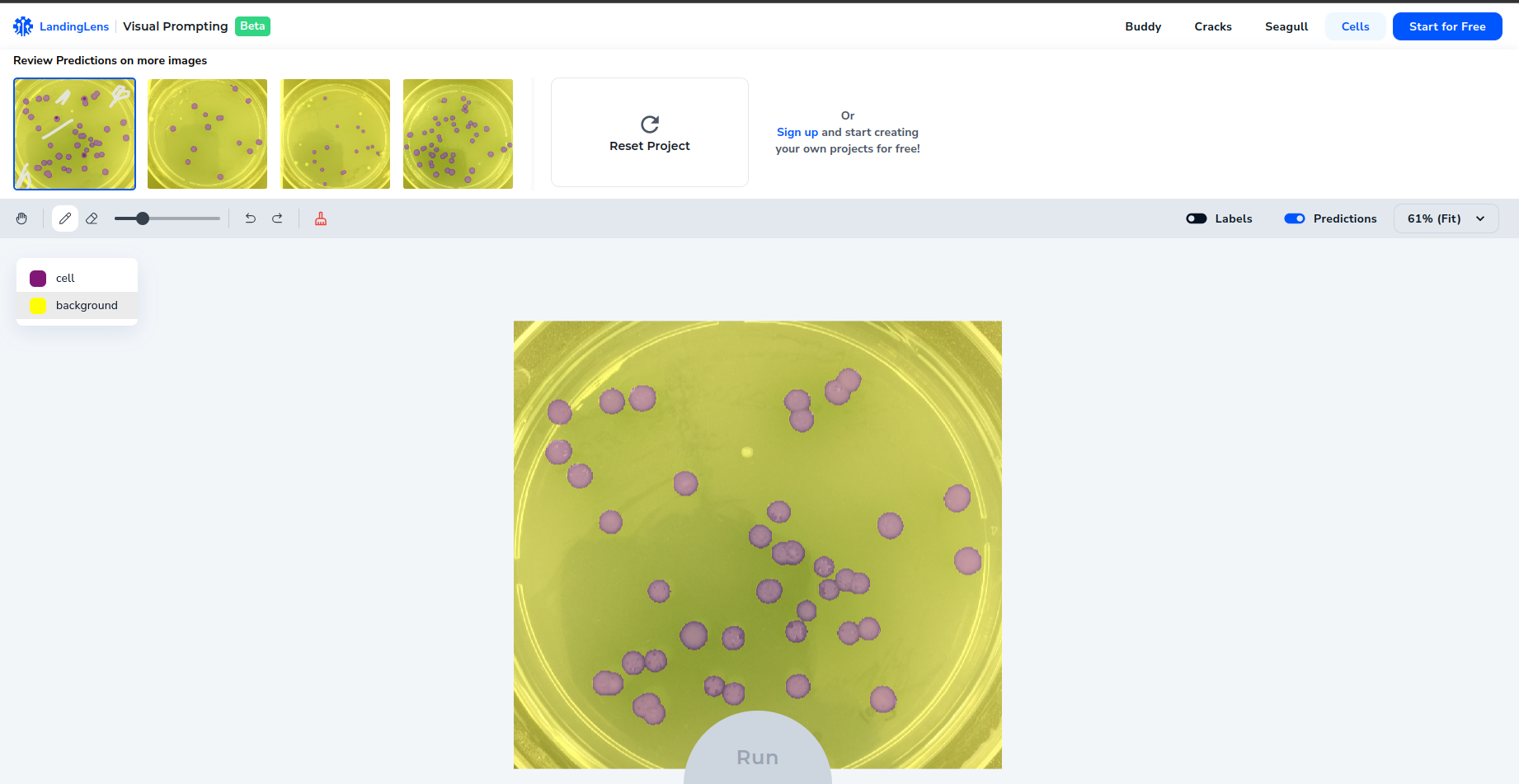
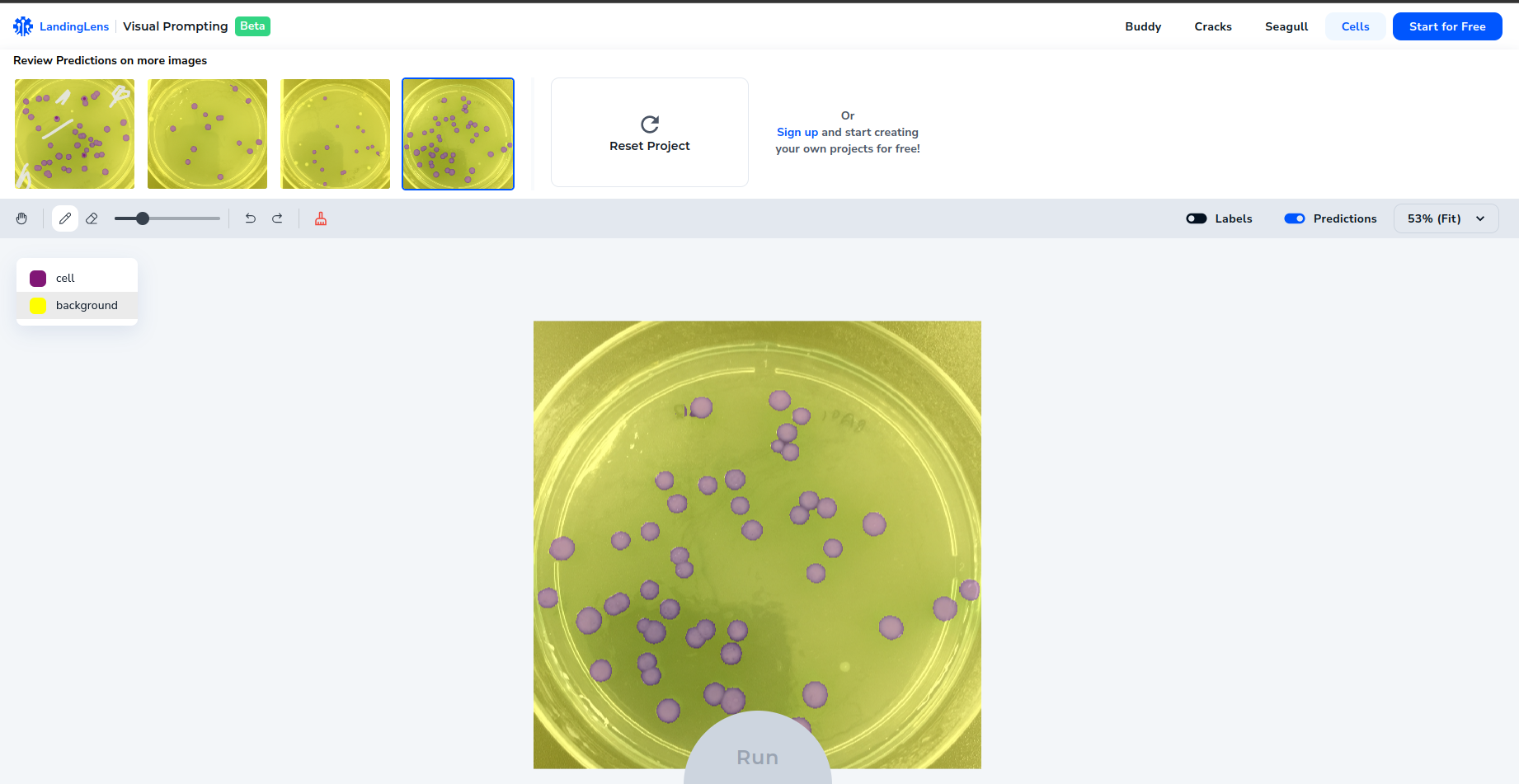
We can check the model prediction and correct them through a visual prompt so that it can learn from those mistakes.
So it is like we are guiding the model by showing him a simple example at first and correcting its mistakes.
This is really a big achievement since it is more efficient and easier for anyone to train a model using it.
Of course, this model is not yet perfect. The use cases for Visual Prompting include 10% by itself and 57.5% with some postprocessing, whereas 32.5% of tasks the model is not ready for them yet.
It is good when texture and colour are available but not good if only we have shapes.
Also, since we provide only a few examples, those examples must be correct, so it is sensitive to wrong inputs.
This not the first model with visual prompting, Meta announced few weeks ago a model called "Segment Anything" that can handle visual prompts, we will talk about it in later article, and explain how those models are trained.