Bias and Variance
عندما نقوم بتدريب نموذج “model”، ربما سنواجه تحديات مثل الملائمة الأكثر من اللازم “overfitting” او الملائمة الأقل من اللازم. “underfitting”.
Overfitting هو سيناريو يحدث عندما يتناسب النموذج الاحصائي تماما مع بيانات التدريب. ان النموذج يتعلم بيانات التدريب جيدا لدرجة انه ينطبق عليها تقريبا، ونظرا لان هذا الانطباق يؤدي الى تباين كبير وقليل من التحيز، فإن هذا يجعل الأداء سيئا على بيانات الاختبار. مما يعني ان النموذج الرياضي لن يعمم بشكل جيد على بيانات الاختبار.
من ناحية أخرى، يعد underfitting سيناريو يعمل فيه النموذج الرياضي بشكل ضعيف في مجموعات التدريب والاختبار. إذا هو حالة من التباين المنخفض والتحيز العالي.
قبل التعمق أكثر، دعونا نفهم مصطلحين مهمين:
- التحيز “bias”: يشير الى الفرق بين التوقع الرياضي لناتج النموذج والناتج الحقيقي. بعبارة أخرى يقيس مدى ملائمة النموذج لبيانات التدريب. عادة ما يكون النموذج ذو التحيز العالي بسيطا للغاية. وقد لا يكون قادرا على فهم الميزات الأساسية الموجودة في البيانات. يمكن ان يؤدي ذلك الى نقص في الملائمة، حيث يكون أداء النموذج سيئا على كل من بيانات التدريب والبيانات الجديدة التي لم يتدرب عليها.
- التباين “variance”: يقيس مدى حساسية النموذج للتقلبات الصغيرة في بيانات التدريب. مما يعني انه إذا قمنا بتغيير البيانات قليلا عن طريق إضافة بعض الضجيج مثلا فان النموذج سيتغير بشكل كبير، على الرغم من ان البيانات لا تزال تتبع نفس التوزع الاحتمالي. عادة ما يكون النموذج ذو التباين الكبير معقدا أكثر من اللازم، وهذا يعني أن النموذج قادر على ملائمة بيانات التدريب بشكل جيد للغاية، ولكنه غير قادر على التعميم على بيانات جديدة لم يتدرب عليها.

من المهم إدراك ان التحيز والتباين ليسا overfitting و underfitting. إذا لم يكن لدينا تحيز وتباين مثالي سيكون لدينا Overfitting أو Underfitting.
ربما سنواجه تحيزا كبيرا و تباينا كبيرا معا لكن لن نواجه overfit و underfit في نفس الوقت.
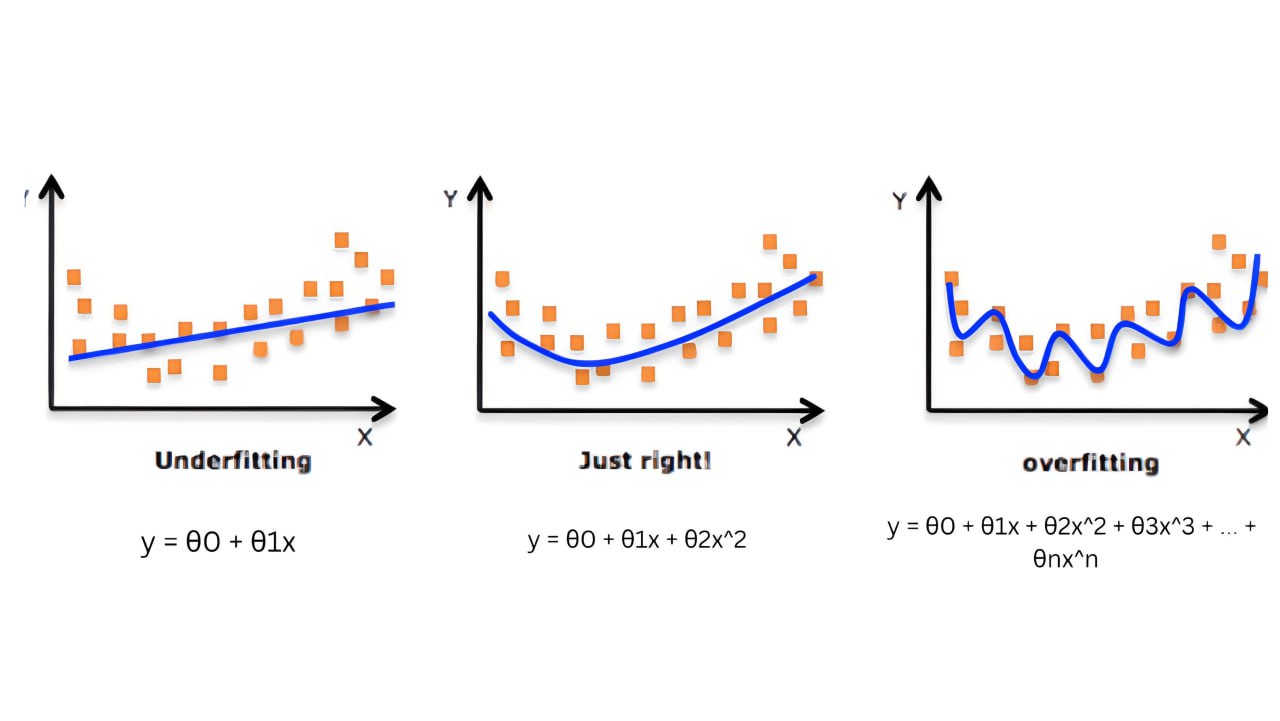
من الناحية التجريبية، يمكننا اكتشاف التحيز على النحو التالي:
- خطأ كبير في التدريب = > تحيز كبير.
- خطأ تدريب صغير = > تحيز صغير.
هذا يعني ان التحيز هو طريقة لوصف الفرق بين العلاقة الفعلية في البيانات، والعلاقة التي تعلمها النموذج.
من الناحية التجريبية، يمكننا اكتشاف التباين على النحو التالي:
- إذا كان للنموذج تباين كبير. في هذه الحالة، قد يكون أداء النموذج جيدًا جدًا في مجموعة التدريب، ولكن بشكل سيئ في مجموعة التحقق، مما يشير إلى أنه ليس مناسبًا للبيانات.
- إذا كان للنموذج تباين منخفض. في هذه الحالة، قد يكون أداء النموذج جيدًا في كل من مجموعة التدريب ومجموعة التحقق، مما يشير إلى أنه مناسب للبيانات.
هنا نحتاج إلى القيام بـ «المقايضة»، ما هذا؟؟
دعونا نفكر في كيفية تقليل التحيز. أسهل طريقة لتحقيق تحيز أقل هي اختيار نموذج أكثر تعقيدًا أو تدريب نموذجنا الحالي لفترة أطول. بعبارة أخرى، نريد استخراج المزيد من المعلومات من مجموعة البيانات الخاصة بنا، حيث نريد أن يتعلم نموذجنا المزيد من البيانات.
وفي الوقت نفسه، يمكن أن ينطبق النموذج ذو التباين العالي مع البيانات، بما في ذلك الضجيج، في حين أن النموذج ذو التباين المنخفض أقل مرونة ولا يمكن أن ينطبق مع بيانات التدريب، خاصة إذا كان هناك بعض الضجيج.
في تعلم الالة، يشير مصطلح «الضجيج» عمومًا إلى التباين العشوائي أو الأخطاء في البيانات التي لا تتعلق بالأنماط أو العلاقات الأساسية بين البيانات التي يحاول النموذج تعلمها. يمكن أن ينشئ الضجيج بسبب عوامل مختلفة مثل أخطاء القياس أو مشكلات جمع البيانات أو مصادر أخرى.
بعبارة أخرى، الضجيج هو التباين العشوائي غير المرغوب في البيانات، في حين أن التباين هو قدرة النموذج على التقاط أو ملائمة هذا الفرق. من المرجح أن يتناسب النموذج ذو التباين العالي مع الضوضاء في البيانات، بينما من المرجح أن يتجاهل النموذج ذو التباين المنخفض الضوضاء ويلتقط الأنماط الأساسية.
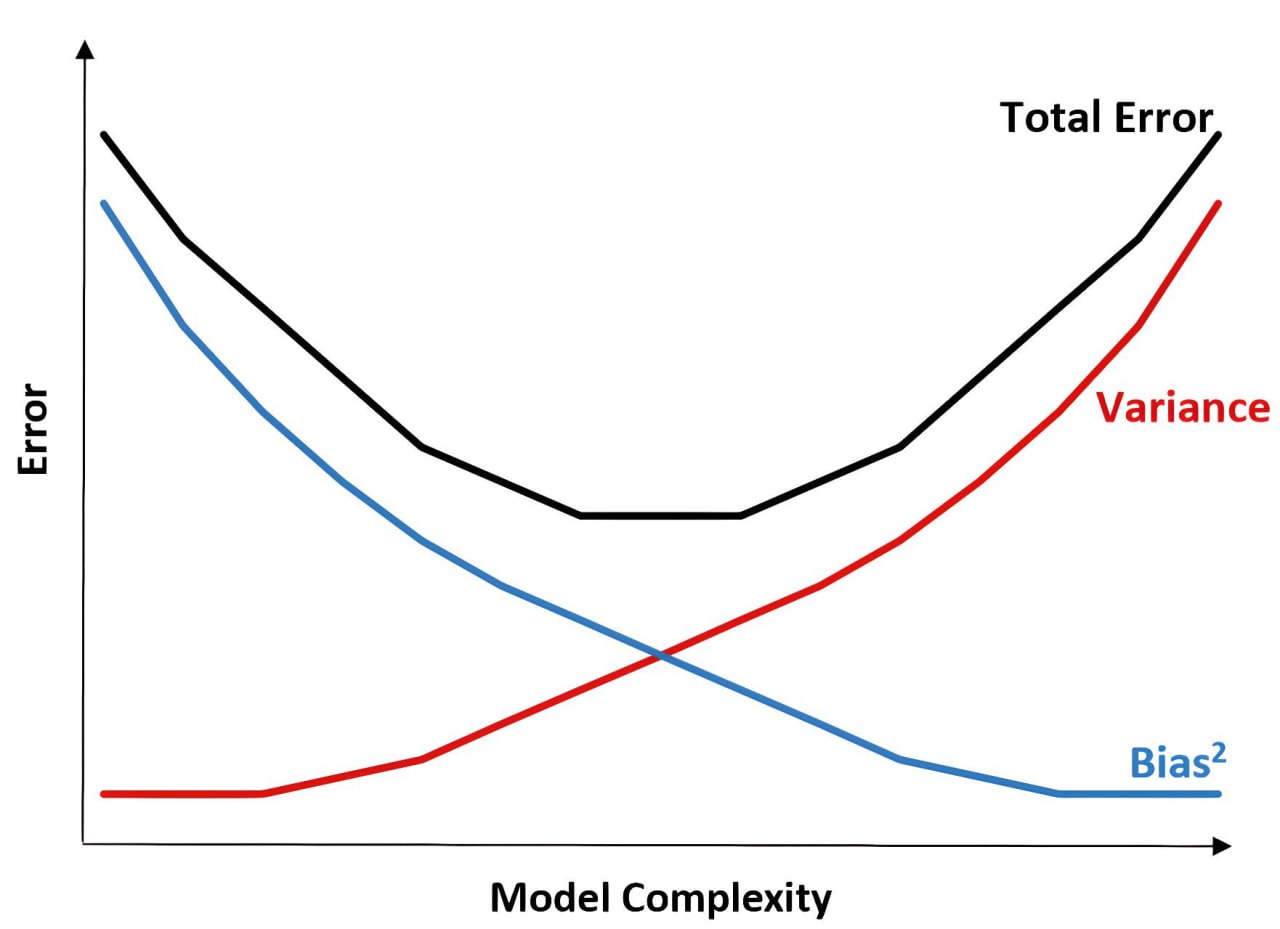
لذلك يبدو أن هناك نوعًا من «المقايضة» بين التحيز والتباين. يمكنك فقط تقليل تحيزك كثيرًا حتى يبدأ تباينك في الزيادة. في هذه المرحلة، قد تفكر في رسم بياني مثل هذا:
فيما يلي بعض الأسباب الشائعة لحدوث الملائمة الأكثر من اللازم:
- عدم كفاية بيانات التدريب: إذا كانت كمية بيانات التدريب صغيرة للغاية، فقد يحفظ النموذج أمثلة التدريب بدلاً من تعلم الأنماط الأساسية، مما يؤدي إلى الإفراط في الملائمة.
- نموذج معقد للغاية: إذا كان النموذج معقدًا للغاية، فقد يحتوي على العديد من المعاملات أو يكون مرنًا للغاية، مما يسمح له بأن يلائم الضجيج في بيانات التدريب بدلاً من الأنماط الأساسية.
- القيم المتطرفة: إذا كانت بيانات التدريب تحتوي على قيم متطرفة بعيدة عن النطاق النموذجي للقيم، فقد يتناسب النموذج مع هذه القيم المتطرفة ويؤدي أداءً سيئًا على البيانات النموذجية.
من ناحية أخرى، يمكن أن يحدث نقص في الملائمة في الحالات التالية:
- تعقيد النموذج غير الكافي: إذا كان النموذج بسيطًا جدًا، فقد لا يكون قادرًا على التقاط الأنماط الأساسية في بيانات التدريب، مما يؤدي إلى نقص الملائمة.
- عدم كفاية وقت التدريب: إذا لم يتم تدريب النموذج عدد كافٍ من التكرارات، فقد لا يكون لديه الوقت الكافي لمعرفة الأنماط الأساسية في بيانات التدريب، مما يؤدي إلى نقص الملائمة.
- اختيار الميزات: إذا لم تكن الميزات أو المتغيرات المستخدمة لتدريب النموذج ذات صلة بالمشكلة أو كان من غير الممكن استنتاج الأنماط الأساسية من خلالها.
و لكن كيف نحل هذه المشاكل؟
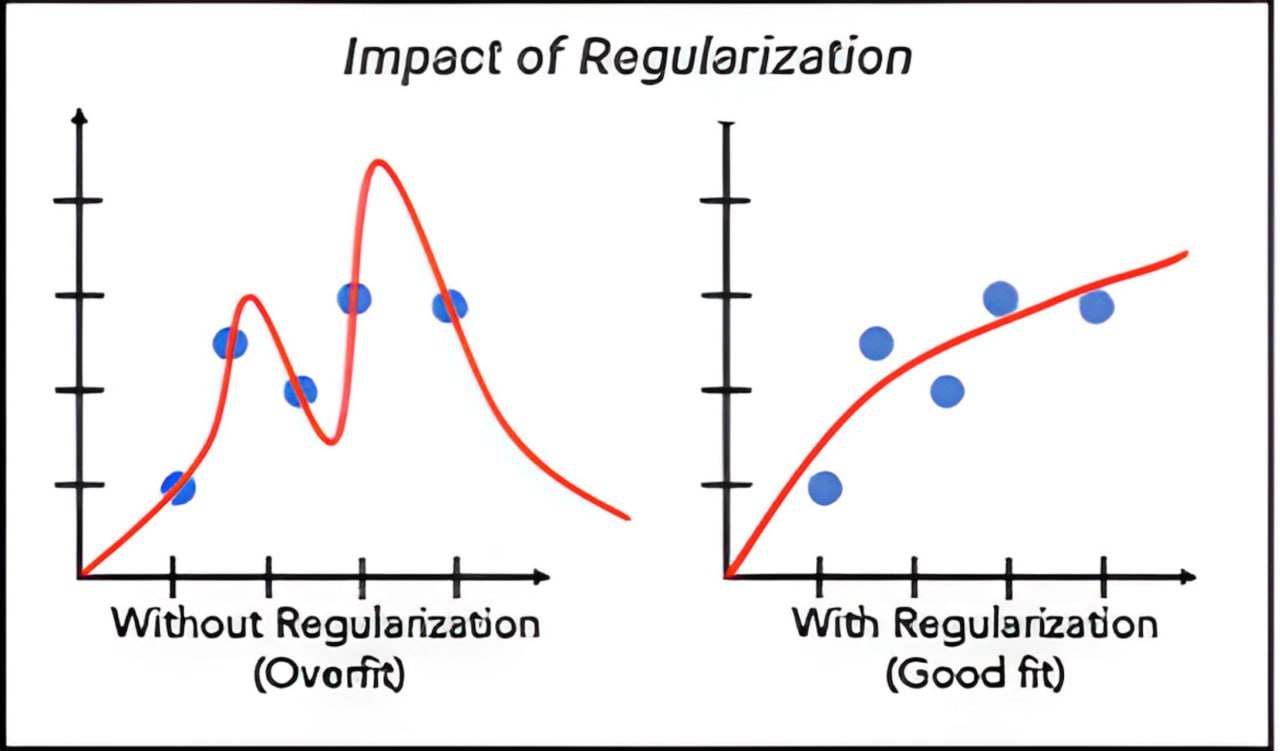
لنبدأ بالأكثر تعقيدًا: المبالغة في الملائمة، هناك أربع تقنيات رئيسية:
Regularization
الضبط هو أحد أهم مفاهيم تعلم الالة. إنها تقنية تستخدم لمنع النموذج من الإفراط في الملائمة. ويمكن استخدامها بطريقة تسمح بالحفاظ على جميع المتغيرات أو المميزات في النموذج عن طريق تقليل قيمة المتغيرات، وبالتالي، بغض النظر عن الحفاظ على الدقة، فإنها تحافظ أيضًا على تعميم النموذج.
في تقنية الضبط، يمكننا تقليل قيمة الميزات مع المحافظة على عددها.
سنتحدث عن هذه التقنية بتعمق أكبر في مقال قادم.
تدعيم البيانات data augmentation
هذه مجموعة من التقنيات المستخدمة لزيادة حجم مجموعة البيانات بشكل مصطنع عن طريق تطبيق التحويلات على البيانات الحالية. على سبيل المثال، في حالة الصور، يمكنك قلب الصور أفقيًا أو عموديًا، أو قصها أو تدويرها. يمكنك أيضًا تحويلها إلى صورة رمادية أو تغيير تشبع اللون. بالطبع، ليست كل التحويلات مفيدة في كل حالة. وفي بعض الحالات، لن ينخدع النموذج بها على أنها بيانات جديدة.
باختصار، يمكن أن يكون تدعيم البيانات أداة قوية للغاية ولكنها تتطلب فحصًا دقيقًا وفهمًا لبياناتك.
إزالة ميزات من البيانات
في بعض الأحيان، قد يفشل نموذجك في التعميم لمجرد أن البيانات التي تم تدريبه عليها كانت معقدة للغاية وأن النموذج فاته الأنماط التي كان يجب اكتشافها. يمكن أن تساعد إزالة بعض الميزات وجعل بياناتك أبسط في تقليل الملائمة المفرطة.
إضافة المزيد من البيانات
يكون نموذجك مفرط في الملائمة عندما يفشل في التعميم على البيانات الجديدة. لذا، فإن إعادة تدريبه على مجموعة بيانات أكبر وأكثر ثراءً وتنوعًا يجب أن تحسن أدائه.
ومن المؤسف أن الحصول على مزيد من البيانات قد يكون صعبا للغاية؛ إما لأن جمعها مكلف للغاية أو لأن القليل جدا من العينات يتم إنشاؤها بانتظام. في هذه الحالة، قد يكون من الجيد استخدام تقنية تدعيم البيانات.
من المهم أن نفهم أن الملائمة المفرطة مشكلة معقدة. ستواجه الأمر بشكل دائم عندما تطور نموذجًا للتعلم العميق ولا يجب أن تشعر بالإحباط إذا كنت تكافح لمعالجته. حتى مهندسي ML الأكثر خبرة يقضون الكثير من الوقت في محاولة حلها.
من أجل مشكلة عدم الملائمة: إليك ما يمكننا تجربته:
زيادة تعقيد النموذج
قد يكون نموذجك غير مناسب لمجرد أنه ليس معقدًا بما يكفي لالتقاط الأنماط في البيانات. غالبًا ما يساعد استخدام نموذج أكثر تعقيدًا، على سبيل المثال عن طريق التحول من نموذج خطي إلى نموذج غير خطي أو عن طريق إضافة طبقات مخفية إلى شبكتك العصبونية، في حل النقص في الملائمة.
الحد من الضبط regularization
غالبًا ما يتم تضمين معاملات الضبط بشكل افتراضي في الخوارزميات لمنع الملائمة المفرطة، ولكن في بعض الأحيان يمكن أن تعيق التعلم. عادة ما يساعد تقليل قيمها من تخفيف هذه المشكلة.
إضافة ميزات إلى بيانات التدريب
على عكس التناسب المفرط، قد يكون نموذجك غير مناسب لأن بيانات التدريب بسيطة للغاية. قد تفتقر إلى الميزات التي ستجعل النموذج يكتشف الأنماط ذات الصلة لإجراء تنبؤات دقيقة. يمكن أن تساعد إضافة الميزات والتعقيد إلى بياناتك في التغلب على نقص الملائمة.
إضافة المزيد من البيانات لن يساعد في حل هذه المشكلة. في الواقع، إذا كانت بياناتك تفتقر إلى الميزات الحاسمة للسماح لنموذجك باكتشاف الأنماط، فيمكنك مضاعفة حجم مجموعة التدريب الخاصة بك بمقدار 2 أو 5 أو حتى 10، فلن تجعل الخوارزمية الخاصة بك أفضل!
لسوء الحظ، يعتقد الكثير من المهندسين أن إلقاء المزيد من البيانات للنموذج سيحل المشكلة بغض النظر عن سببها. عندما تعرف كم يمكن أن يكون جمع البيانات مكلفاً،ستدرك أن هذا خطأ يمكن أن يضر بالمشروع.